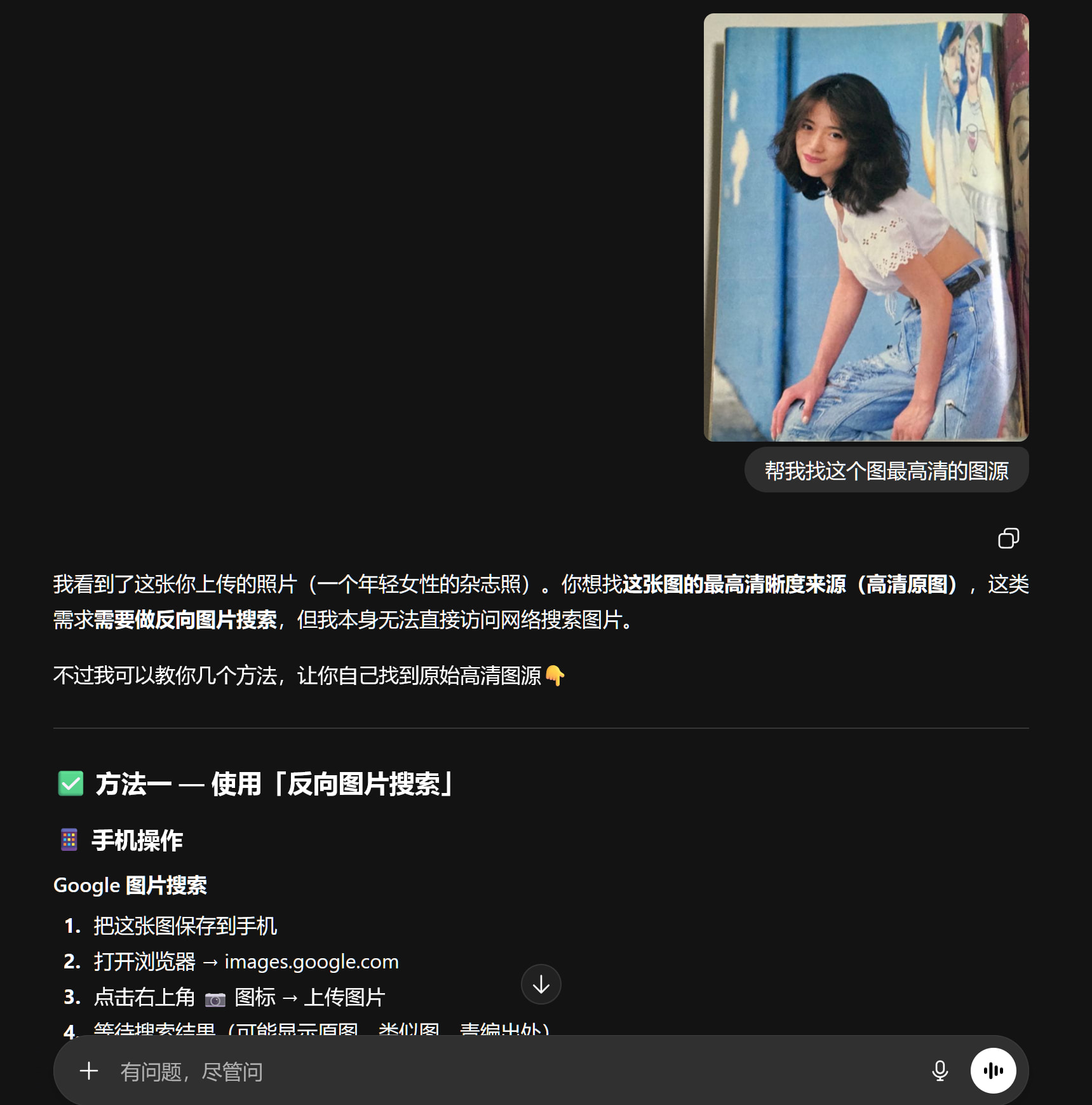
LLM по своей сути занимается вероятностной генерацией текста; это не настоящий поисковик и он не может в реальном времени гонять по всему интернету обратный поиск по картинкам. Его «просмотр изображения» — скорее распознавание стиля и признаков, а не поштучное сравнение с базой данных.
Поиск источника в высоком разрешении на базовом уровне опирается на индексацию изображений, хэширование признаков и сопоставление с фотобанками — это компетенция поисковых систем, а не сильная сторона LLM. Если само изображение не известное, не со звездой или не из классического журнального материала, то в сети изначально мало индексируемых HD-версий, и GPT практически не сможет «из воздуха» его найти. По сути, на уровне принципа это очень трудно действительно хорошо сделать с помощью LLM.
С редкими картинками — только традиционный поиск по изображению и сортировка по размеру, ничего не поделаешь.